|
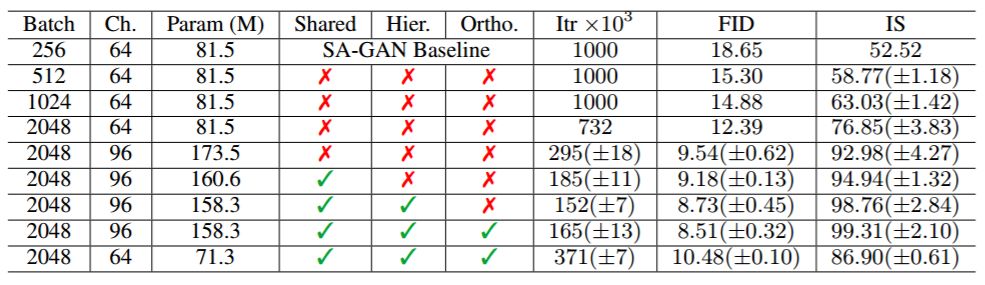
在向 ICLR 2019 提交的论文中,有一篇 GAN 生成图像的论文引起了所有人的注意,很多学者惊呼:不敢相信这样高质量的图像竟是 AI 生成出来的。其中生成图像的目标和背景都高度逼真、边界自然,并且图像插值每一帧都相当真实,简直能称得上「创造物种的 GAN」。该论文还引起了 Oriol Vinyals、Ian Goodfellow 的关注。 论文:LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS 尽管近期由于生成图像建模的研究进展,从复杂数据集例如 ImageNet 中生成高分辨率、多样性的样本仍然是很大的挑战。为此,在这篇提交到 ICLR 2019 的论文中,研究者尝试在最大规模的数据集中训练生成对抗网络,并研究在这种规模的训练下的不稳定性。研究者发现应用垂直正则化(orthogonal regularization)到生成器可以使其服从简单的「截断技巧」(truncation trick),从而允许通过截断隐空间来精调样本保真度和多样性的权衡。这种修改方法可以让模型在类条件的图像合成中达到当前最佳性能。当在 128×128 分辨率的 ImageNet 上训练时,本文提出的模型—BigGAN—可以达到 166.3 的 Inception 分数(IS),以及 9.6 的 Frechet Inception 距离(FID),而之前的最佳 IS 和 FID 仅为 52.52 和 18.65。 图 1:由 BigGAN 生成的类条件样本。 近年来生成图像建模领域进展迅速,GAN 的提出为我们带来了能直接从数据中学习生成高保真度和多样图像的模型。GAN 的训练是动态的,并且对几乎所有层面的设置都很敏感(从最优化参数到模型架构),但有大量的研究在经验和理论上获得了在多种设置中实现稳定训练的洞察。尽管得到了这样的进展,当前在条件 ImageNet 建模上的当前最佳结果仍然仅达到了 52.5 的 IS,而真实数据有 233 的 IS。 在这项研究中,作者成功地将 GAN 生成图像和真实图像之间的保真度和多样性 gap 大幅降低。本研究做出的贡献如下: 展示了 GAN 可以从训练规模中显著获益,并且能在参数数量很大和八倍批大小于之前最佳结果的条件下,仍然能以 2 倍到 4 倍的速度进行训练。作者引入了两种简单的生成架构变化,提高了可扩展性,并修改了正则化方案以提升条件化(conditioning),这可论证地提升了性能。 作为修改方法的副作用,该模型变得服从「截断技巧」,这是一种简单的采样技术,允许对样本多样性和保真度进行精细控制。 发现大规模 GAN 带来的不稳定性,并对其进行经验的描述。从这种分析中获得的洞察表明,将一种新型的和已有的技术结合可以减少这种不稳定性,但要实现完全的训练稳定性必须以显著降低性能为代价。 本文提出的修改方法大幅改善了类条件 GAN 的性能。当在 128×128 分辨率的 ImageNet 上训练时,本文提出的模型—BigGAN—可以达到 166.3 的 Inception 分数(IS),以及 9.6 的 Frechet Inception 距离(FID),而之前的最佳 IS 和 FID 仅为 52.52 和 18.65。 研究者还成功地在 256×256 分辨率和 512×512 分辨率的 ImageNet 上训练了 BigGAN,并在 256×256 分辨率下达到 233.0 的 IS 和 9.3 的 FID,在 512×512 分辨率下达到了 241.4 的 IS 和 10.9 的 FID。最后,研究者还尝试在更大规模的数据集上训练,结果表明其提出的架构设计可以很好地从 ImageNet 中迁移到其它图像数据。 扩展 GAN 的规模 研究者从为基线模型增加批大小开始,并立刻发现了这样做带来的好处。表 1 的 1 到 4 行表明按 8 的倍数增加批大小可以将当前最佳的 IS 提高 46%。研究者假设这是由于每个批量覆盖了更多的模式,为生成器和鉴别器都提供了更好的梯度信息。这种扩展带来的值得注意的副作用是,模型以更少的迭代次数达到了更好的性能,但变得不稳定并且遭遇了完全的训练崩溃。研究者在论文第 4 部分讨论了原因和后果。因此在实验中,研究者在崩溃刚好发生之后立刻停止训练,并从之前保存的检查点进行结果报告。 表 1:BigGAN 的控制变量研究结果。 然后,研究者增加了每个层 50% 的宽度(通道数量),这大致在生成器和鉴别器中都翻倍了参数数量。这导致了进一步的 21% 的 IS 提升,研究者假设这是由于模型相对于数据集复杂度的容量的增加。将深度翻倍在 ImageNet 模型上并不能得到相同的优化效应,反而会降低性能。 图 2:(a)增加截断的效应。从左到右,阈值=2, 1.5, 1, 0.5, 0.04。(b)应用截断和性能差的条件生成模型的饱和度伪影。 研究者注意到 G 中的用于条件批归一化层的类嵌入 c 包含大量的权重。研究者选择使用共享嵌入,其线性投射到每个层的增益和偏差,而没有为每个嵌入使用单独的层。这降低了计算和内存成本,并提升了 37% 的训练速度(用达到特定性能需要的迭代次数衡量)。接下来,研究者使用了多个层级隐空间,其中噪声向量 z 被馈送到 G 的多个层,而不仅是初始层。 这种设计的直觉来源于,让 G 使用隐空间直接影响不同分辨率和层级下的特征。在本文提出的架构中,这很容易通过将 z 分离为每个分辨率一段,并将 z 的每段和条件向量(其投射到批归一化增益和偏差)拼接来实现。以前的研究曾经考虑过这种概念的变体(Goodfellow et al., 2014; Denton et al., 2015),本文研究者的贡献在于对这种设计进行了小幅修改。层级隐空间优化了计算和内存成本(主要通过减少第一个线性层的参数预算),这提供了大约 4% 的性能提升,并进一步提升了 18% 的训练速度。 图 4:截断阈值 0.5 下的模型采样(a-c),以及部分训练模型类泄露(class leakage)示例。 表 2:在不同分辨率下的模型评估结果。研究者报告了未使用截断(第 3 列),最佳 FID 分数(第 4 列),验证数据的最佳 IS(第 5 列),以及最高的 IS(第 6 列)。标准差通过至少三次随机初始化计算得到。 图 6:由 BigGAN 在 512×512 分辨率下生成的其它样本。 图 8:z、c 配对下的图像插值。
|  /1
/1 
 |Archiver|手机版|小黑屋|陕ICP备15012670号-1
|Archiver|手机版|小黑屋|陕ICP备15012670号-1





 发表于 2018-10-3 18:25:52
发表于 2018-10-3 18:25:52