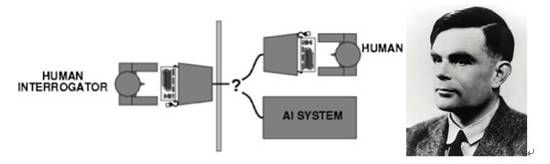
’‚ŃĹńÍ»ňĻ§÷«ń‹£®Artificial Intelligence£©Ńž”Ú»»ń÷∑«∑≤£¨≤ĽĹŲŅ∆ľľĺřÕ∑∑◊∑◊∑ĘѶAI»°Ķ√ľľ ű”Ž≤ķ∆∑ĶńÕĽ∆∆£¨ĽĻ”–÷ŕ∂ŗ≥űīī∆ů“ĶĽŮĶ√∑ÁŌ’◊ ĪĺĶń«ŗŪý£¨ľłļű√Ņ÷‹∂ľŅ…“‘ŅīĶĹŌŗĻōŃž”Ú≥űīīĻęňĺĽŮĶ√Õ∂◊ ĶńĪ®Ķņ°£AiphaGo‘ŕőß∆Ś”őŌ∑÷–īů §ņÓ ņ Į Ļ»ň√«∂‘AIĻőńŅŌŗŅīĶńÕ¨ Ī“≤“ż∑ĘŃň∂‘AIĹę»ÁļőłńĪšő“√«…ķĽÓĶńňľŅľ°£ ∆š Ķ£¨»ňĻ§÷«ń‹ī”…Ō ņľÕ40ńÍīķĶģ…ķ÷ŃĹŮ£¨ĺ≠ņķŃň“Ľīő”÷“ĽīőĶń∑Ī»Ŕ”ŽĶÕĻ»£¨Ō¬√śő“√«ĺÕņīĽōĻňŌ¬Ļż»•įŽłŲ ņľÕņÔ»ňĻ§÷«ń‹Ķń∑Ę’Ļņķ≥Ő°£ |»ňĻ§÷«ń‹∑Ę’ĻĶń∆ŖłŲĹ◊∂ő 1.∆ū‘īĹ◊∂ő£ļ»ňĻ§÷«ń‹’ś’żĶģ…ķ”ŕ20 ņľÕĶń40 - 50ńÍīķ°£’‚∂ő ĪľšņÔ£¨īůŃŅī” ¬ ż—ß°ĘĻ§≥Ő°Ęľ∆ň„ĽķĶ»—–ĺŅŃž”ÚĶńŅ∆—ßľ“√«Ņ™ ľŐĹŐ÷°į»ňĻ§īůń‘°ĪĶńŅ…ń‹–‘°£1950ńÍįĘņľ ÕľŃť£®Alan Turing£©∑ĘĪŪŃňŐ‚ő™°įĽķ∆ųń‹ňľŅľ¬ū°ĪĶń÷Ý√Ż¬Řőń£¨ŐŠ≥ŲŃň÷Ý√ŻĶńÕľŃť≤‚ ‘ņī∂®“ŚĽķ∆ų÷«ń‹°£ňŻňĶ÷Ľ“™”–30%Ķń»ňņŗ≤‚ ‘’Ŗ‘ŕ5∑÷÷”ńŕőř∑®∑÷Īś≥ŲĪĽ≤‚ ‘∂‘ŌůĺŅĺĻ «»ňņŗĽĻ «Ľķ∆ų£¨ĺÕŅ…“‘»Ōő™Ľķ∆ųÕ®ĻżŃňÕľŃť≤‚ ‘°£
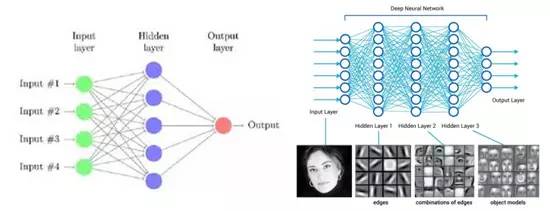
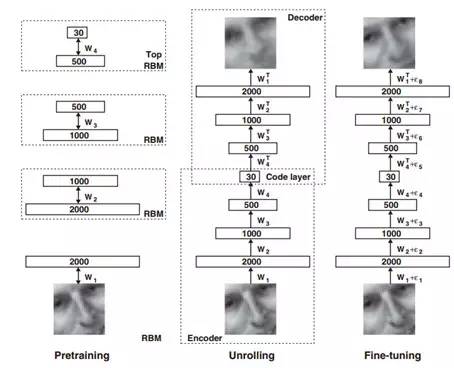
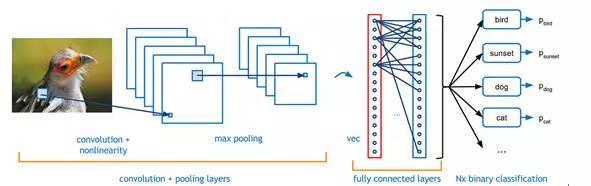
Õľ1£ļÕľŃť≤‚ ‘ 2.Ķŕ“ĽīőĽ∆Ĺū Ī∆ŕ£ļ◊®“Ķ ű”Ô°į»ňĻ§÷«ń‹°Ī£®Artificial Intelligence£©Ķģ…ķ”ŕ1956ńÍĶńīÔŐō√¨ňĻĽŠ“ť£¨”…ľ∆ň„ĽķŅ∆—ßľ“John McCarthy ◊īő’ż ĹŐŠ≥Ų°£īÔŐō√¨ňĻĽŠ“ť÷ģļůĶń ģ∂ŗńÍ «»ňĻ§÷«ń‹ĶńĶŕ“ĽīőĽ∆Ĺū Īīķ£¨Ņ∆—ßľ“√«∂‘»ňĻ§÷«ń‹Ķń«įĺį¬ķĽ≥ľ§«ť£¨īůŇķ—–ĺŅ’Ŗ∆ňŌÚ’‚“Ľ–¬Ńž”Ú£¨“Ľ–©∂•ľ‚łŖ–£Ĺ®ŃĘĶń»ňĻ§÷«ń‹ŌÓńŅĽŮĶ√ŃňARPAĶ»ĽķĻĻĶńīůĪ ĺ≠∑—£¨…ű÷Ń”–—–ĺŅ’Ŗ»Ōő™Ľķ∆ųļ‹ŅžĺÕń‹Őśīķ»ňņŗÕÍ≥…“Ľ«–Ļ§◊ų°£ 3.Ķŕ“ĽīőĶÕĻ»£ļĶĹŃň70ńÍīķ£¨”…”ŕľ∆ň„Ľķ–‘ń‹∆ŅĺĪ°Ęľ∆ň„łī‘”–‘Ķń‘Ų≥§“‘ľį żĺ›ŃŅĶń≤Ľ◊„£¨ļ‹∂ŗ»ňĻ§÷«ń‹Ņ∆—–ŌÓńŅĶń≥–ŇĶőř∑®∂“Ō÷£¨Ī»»Áľ∆ň„Ľķ ”ĺűłýĪĺ’“≤ĽĶĹ◊„ĻĽĶń żĺ›Ņ‚ĹÝ––—ĶŃ∑£¨÷«ń‹“≤ĺÕőřī”Őł∆ū°£“Úīň£¨—ßĹÁĹę»ňĻ§÷«ń‹∑÷ő™ŃĹ÷÷£ļń—“‘ ĶŌ÷Ķń«Ņ»ňĻ§÷«ń‹ļÕŅ…“‘≥Ę ‘Ķń»ű»ňĻ§÷«ń‹°£«Ņ»ňĻ§÷«ń‹ĺÕ «ń‹ŌŮ»ňņŗ“Ľ—ý÷ī––Õ®”√»őőŮ£Ľ»ű»ňĻ§÷«ń‹‘Ú÷Ľń‹ī¶ņŪĶ•“Ľő Ő‚°£ļ‹∂ŗŌÓńŅĶńĹÝ∂»Õ£÷Õ≤Ľ«į“≤”įŌžŃň◊ ÷ķ◊ ĹūĶń◊ŖŌÚ£¨AIŌ›»ŽŃň≥§īÔ żńÍ÷ģĺ√ĶńĶÕĻ»°£ 4.◊®ľ“ŌĶÕ≥Ķń≥ŲŌ÷£ļ70ńÍīķ÷ģļů£¨—ß űĹÁ÷ūĹ•Ĺ” ‹–¬Ķńňľ¬∑£ļ»ňĻ§÷«ń‹≤ĽĻ‚“™—–ĺŅň„∑®£¨ĽĻĶ√“ż»Ž÷™ ∂°£”ŕ «£¨◊®ľ“ŌĶÕ≥Ķģ…ķŃň°£ňŁņŻ”√ ż◊÷ĽĮĶń÷™ ∂»•Õ∆ņŪ£¨ń£∑¬ń≥“ĽŃž”ÚĶń◊®ľ“»•Ĺ‚ĺŲő Ő‚°£°į÷™ ∂ī¶ņŪ°ĪŅ™ ľ≥…ő™»ňĻ§÷«ń‹Ķń—–ĺŅ÷ōĶ„°££¨1977ńÍ ņĹÁ»ňĻ§÷«ń‹īůĽŠŐŠ≥Ų°į÷™ ∂Ļ§≥Ő°ĪĶń∆Ű∑Ę£¨rbĶńĶŕőŚīķľ∆ň„Ľķľ∆Ľģ°Ę”ĘĻķĶńįĘ∂Żő¨ľ∆Ľģ°ĘŇ∑÷řĶń”»ņÔŅ®ľ∆ĽģļÕmgĶń–«ľ∆ĽģŌŗľŐ≥ŲŐ®£¨īÝņī◊®ľ“ŌĶÕ≥ĶńłŖňŔ∑Ę’Ļ°£ 5.Ķŕ∂Ģīőĺ≠∑—ő£Ľķ£ļ20 ņľÕ90ńÍīķ÷ģ«įĶńīů≤Ņ∑÷»ňĻ§÷«ń‹ŌÓńŅ∂ľ «ŅŅzfĽķĻĻ◊ ÷ķ£¨ĺ≠∑—◊ŖŌÚ÷ĪĹ””įŌž◊Ň»ňĻ§÷«ń‹Ķń∑Ę’Ļ°£80ńÍīķ÷–∆ŕ£¨∆ĽĻŻļÕIBMĶńŐ® ĹĽķ–‘ń‹“—ĺ≠≥¨ĻżŃň‘ň”√◊®ľ“ŌĶÕ≥ĶńÕ®”√–Õľ∆ň„Ľķ£¨◊®ľ“ŌĶÕ≥Ķń∑ÁĻ‚ňś÷ģÕ »•£¨»ňĻ§÷«ń‹—–ĺŅ‘Ŕīő‘‚”Ųĺ≠∑—ő£Ľķ°£ 6.IBMĶń…Óņ∂ļÕWatson£ļ◊®ľ“ŌĶÕ≥÷ģļů£¨Ľķ∆ų—ßŌį≥…ő™Ńň»ňĻ§÷«ń‹ĶńĹĻĶ„£¨∆šńŅĶń «»√Ľķ∆ųĺŖĪł◊‘∂Į—ßŌįĶńń‹Ń¶£¨Õ®Ļżň„∑® ĻĶ√Ľķ∆ųń‹ĻĽī”īůŃŅņķ ∑ żĺ›÷–—ßŌįĻś¬…≤Ę∂‘–¬Ķń—ýĪĺ◊ų≥ŲŇ–∂Ō ∂Īū°£°£‘ŕ’‚“ĽĹ◊∂ő£¨IBMőř“… «»ňĻ§÷«ń‹Ńž”ÚĶńŃž–š£¨1996ńÍIBMĻęňĺĶńAIŌĶÕ≥°į…Óņ∂°Ī’Ĺ §ŃňĻķľ Ōů∆Ś ņĹÁĻŕĺŁŅ®ňĻŇѬř∑Ú£¨2011ńÍIBMĻęňĺĶńAIŌĶÕ≥Watson‘ŕĶÁ ”ő īūĹŕńŅ÷–’Ĺ §»ňņŗ—° ÷°£ļů’Ŗ…śľįĶĹ∑ŇĶĹŌ÷‘໑»Ľ «ń—Ő‚Ķń◊‘»Ľ”Ô—‘ņŪĹ‚£¨≥…ő™Ľķ∆ųņŪĹ‚»ňņŗ”Ô—‘ĶńņÔ≥ŐĪģ ¬ľĢ°£ 7.…Ó∂»—ßŌįĶń«Ņ ∆Š»∆ū£ļ…Ó∂»—ßŌį «Ľķ∆ų—ßŌįĶńĶŕ∂Ģīőņň≥Ī°£2013ńÍ4‘¬£¨°∂¬ť °ņŪĻ§—ß‘ļľľ ű∆ņ¬Ř°∑Ĺę…Ó∂»—ßŌįŃ–ő™2013ńÍ ģīůÕĽ∆∆–‘ľľ ű÷ģ ◊°£∆š Ķ£¨…Ó∂»—ßŌį≤Ę∑«–¬ ¬őÔ£¨ňŁ «īęÕ≥…Ůĺ≠ÕݬÁ£®Neural Network£©Ķń∑Ę’Ļ£¨ŃĹ’Ŗ≤…”√ŃňŌŗň∆Ķń∑÷≤„ĹŠĻĻ£¨≤ĽÕ¨÷ģī¶‘ŕ”ŕ…Ó∂»—ßŌį≤…”√Ńň≤ĽÕ¨Ķń—ĶŃ∑Ľķ÷∆£¨ĺŖĪł«ŅīůĶńĪŪīÔń‹Ń¶°£īęÕ≥…Ůĺ≠ÕݬÁ‘Ýĺ≠‘ŕĽķ∆ų—ßŌįŃž”ÚĽūĻż“Ľ’ů◊”£¨Ķęļůņī”…”ŕ≤ő żń—”ŕĶų’ŻļÕ—ĶŃ∑ňŔ∂»¬żĶ»ő Ő‚÷ūĹ•Ķ≠≥ŲŃň»ň√«Ķń ”“į°£ Ķę «”–“ĽőĽĹ–Geoffrey HintonĶń∂ŗ¬◊∂ŗīů—ßņŌĹŐ ŕ∑«≥£÷ī◊Ň”ŕ…Ůĺ≠ÕݬÁĶń—–ĺŅ£¨≤ĘļÕYoshua Bengio°ĘYann LeCun“Ľ∆ūŐŠ≥ŲŃňŅ…––Ķń…Ó∂»—ßŌį∑Ĺįł°£2012ńÍHintonĶń—ß…ķ‘ŕÕľ∆¨∑÷ņŗĺļ»ŁImageNet…ŌīÚį‹ŃňGoogle£¨∂Ŕ Ī»√—ß űĹÁļÕĻ§“ĶĹÁĽ©»Ľ£¨őŁ“żŃňĻ§“ĶĹÁ∂‘…Ó∂»—ßŌįĶńīůĻśń£Õ∂»Ž°£2012ńÍGoogle Brain”√16000łŲCPUļňĶńľ∆ň„∆ĹŐ®—ĶŃ∑10“ŕ…Ůĺ≠‘™Ķń…Ó∂»ÕݬÁ£¨őřÕ‚ĹÁł……śŌ¬◊‘∂Į ∂Īū≥ŲŃň°įCat°Ī£ĽHintonĶńDNN≥űīīĻęňĺĪĽGoogle ’Ļļ£¨HintonłŲ»ň“≤ľ”»ŽŃňGoogle£Ľ∂ÝŃŪ“ĽőĽīůŇ£LeCunľ”»ŽFacebook£¨≥Ų»őAI Ķ—ť “÷ų»ő°£≤ĽĹŲŅ∆ľľĺřÕ∑√«ľ”īů∂‘AIĶńÕ∂»Ž£¨“ĽīůŇķ≥űīīĻęňĺ≥ň◊Ň…Ó∂»—ßŌįĶń∂ę∑Á”ŅŌ÷£¨ ĻĶ√»ňĻ§÷«ń‹Ńž”Ú»»ń÷∑«∑≤°£ |»ňĻ§÷«ń‹÷ģ÷ų“™“ż«ś£ļ…Ó∂»—ßŌį Ľķ∆ų—ßŌį∑Ę’Ļ∑÷ő™ŃĹłŲĹ◊∂ő£¨∆ū‘ī”ŕ…Ō ņľÕ20ńÍīķĶń«≥≤„—ßŌį£®ShallowLearning£©ļÕ◊ÓĹŁľłńÍ≤ŇĽū∆ūņīĶń…Ó∂»—ßŌį£®Deep Learning£©°£«≥≤„—ßŌįĶńň„∑®÷–◊ÓŌ»ĪĽ∑Ę√ųĶń «…Ůĺ≠ÕݬÁĶń∑īŌÚīę≤•ň„∑®£®back propagation£©°£ő™ ≤√ī≥∆÷ģő™«≥≤„ńō£¨“Úő™ĶĪ ĪĶń—ĶŃ∑ń£–Õ «÷Ľļ¨”–“Ľ≤„“Ģļ¨≤„Ķń«≥≤„ń£–Õ°£’‚÷÷ń£–Õ”–łŲļ‹īůĶń»űĶ„£¨ń«ĺÕ «”–Ōř≤ő żļÕľ∆ň„Ķ•‘™£¨Őō’ųĪŪīÔń‹Ń¶»ű°£ …Ō ņľÕ90ńÍīķ£¨—ß űĹÁŐŠ≥Ų“ĽŌĶŃ–Ķń«≥≤„Ľķ∆ų—ßŌįń£–Õ£¨įŁņ®∑Á––“Ľ ĪĶń÷ß≥ŇŌÚŃŅĽķSupport Vector Machine£¨BoostingĶ»°£’‚–©ń£–ÕŌŗĪ»īęÕ≥…Ůĺ≠ÕݬÁ‘ŕ–߬ ļÕ◊ľ»∑¬ …Ō∂ľ”–ňýŐŠ…ż°£Ķęļůņī»ň√«∑ĘŌ÷£¨ ∂Īūĺę∂»ĶĹīÔ“Ľ∂®≥Ő∂»ļů£¨ľī Ļ—ĶŃ∑‘Ŕ∂ŗĶń żĺ›£¨‘Ŕ‘ű√īĶų’Ż≤ő ż£¨ĺę∂»“≤őř∑®ľŐ–ÝŐŠłŖ°£ ‘ŕīň∆ŕľš£¨HintonĹŐ ŕ“Ľ÷Ī÷ī◊Ň”ŕ∂ŗ“Ģ≤„…Ůĺ≠ÕݬÁĶńň„∑®—–ĺŅ°£∂ŗ“Ģ≤„…Ůĺ≠ÕݬÁ∆š ĶĺÕ ««≥≤„…Ůĺ≠ÕݬÁĶń…Ó∂»įśĪĺ£¨ ‘Õľ Ļ”√łŁ∂ŗĶń…Ůĺ≠‘™ņīĪŪīÔŐō’ų£¨∆š ĶŌ÷ń—Ķ„÷ų“™‘ŕ”ŕ“‘Ō¬»ż∑Ĺ√ś£ļ BPň„∑®÷–őů≤ÓĶń∑īŌÚīę≤•ňś◊Ň“Ģ≤„Ķń‘Ųľ”∂Ýň•ľű£Ľļ‹∂ŗ ĪļÚ÷Ľń‹īÔĶĹĺ÷≤Ņ◊Ó”ŇĹ‚£Ľ ń£–Õ≤ő ż‘Ųľ”£¨∂‘—ĶŃ∑ żĺ›ĶńŃŅ”–ļ‹łŖ“™«ů£¨»ÁĻŻ≤Ľń‹ŐŠĻ©Ň”īůĶńĪÍ ∂ żĺ›£¨Ņ…ń‹ĽŠĶľ÷¬Ļż∂»łī‘”£Ľ ∂ŗ“Ģ≤„ĹŠĻĻĶń≤ő ż∂ŗ£¨—ĶŃ∑ żĺ›ĶńĻśń£īů£¨–Ť“™ŌŻļńļ‹∂ŗľ∆ň„◊ ‘ī°£ Õľ2£ļīęÕ≥…Ůĺ≠ÕݬÁ”Ž∂ŗ“Ģ≤„…Ůĺ≠ÕݬÁ 2006ńÍ£¨HintonļÕňŻĶń—ß…ķR.R. Salakhutdinov≥…Ļ¶—ĶŃ∑≥Ų∂ŗ≤„…Ůĺ≠ÕݬÁ£¨‘ŕ°∂Science°∑…Ō∑ĘĪŪőń’¬£®Reducingthe dimensionality of data with neural networks£©£¨łńĪšŃň’ŻłŲĽķ∆ų—ßŌįĶńłŮĺ÷°£’‚∆™őń’¬”–ŃĹłŲ÷ų“™ĻŘĶ„£ļ1£©∂ŗ“Ģ≤„…Ůĺ≠ÕݬÁ”–łŁ«ŅīůĶń—ßŌįń‹Ń¶£¨Ņ…“‘ĪŪīÔłŁ∂ŗŐō’ųņī√Ť Ų∂‘Ōů£Ľ2£©—ĶŃ∑…Ó∂»…Ůĺ≠ÕݬÁ Ī£¨Ņ…Õ®ĻżĹĶő¨£®pre-training£©ņī ĶŌ÷°£HintonĹŐ ŕ…Ťľ∆ĶńAutoencoderÕݬÁń‹ĻĽŅžňŔ’“ĶĹļ√Ķń»ęĺ÷◊Ó”ŇĶ„£¨≤…”√őřľŗ∂ĹĶń∑Ĺ∑®Ō»∑÷Ņ™∂‘√Ņ≤„ÕݬÁĹÝ––—ĶŃ∑£¨»Ľļů‘ŔĹÝ––őĘĶų°£ Õľ3£ļÕľŌŮĶń”Ž—ĶŃ∑£¨Īŗ¬Ž°ķĹ‚¬Ž°ķőĘĶų ī”Õľ3ő“√«Ņ…“‘ŅīĶĹ£¨…Ó∂»…Ůĺ≠ÕݬÁ «÷ū≤„ĹÝ––‘§—ĶŃ∑£¨Ķ√ĶĹ√Ņ“Ľ≤„Ķń š≥Ų£ĽÕ¨ Ī“ż»ŽĪŗ¬Ž∆ųļÕĹ‚¬Ž∆ų£¨Õ®Ļż‘≠ ľ š»Ž”ŽĪŗ¬Ž°ķ‘ŔĹ‚¬Ž÷ģļůĶńőů≤Óņī—ĶŃ∑£¨’‚ŃĹ≤Ĺ∂ľ «őřľŗ∂Ĺ—ĶŃ∑Ļż≥Ő£Ľ◊Óļů“ż»Ž”–ĪÍ ∂—ýĪĺ£¨Õ®Ļż”–ľŗ∂Ĺ—ĶŃ∑ņīĹÝ––őĘĶų°£÷ū≤„—ĶŃ∑Ķńļ√ī¶ «»√ń£–Õī¶”ŕ“ĽłŲŔţ»ęĺ÷◊Ó”ŇĶńőĽ÷√»•ĽŮĶ√łŁļ√Ķń—ĶŃ∑–ßĻŻ°£ “‘…ŌĺÕ «Hinton‘ŕ2006ńÍŐŠ≥ŲĶń÷Ý√ŻĶń…Ó∂»—ßŌįŅÚľ‹£¨∂Ýő“√« Ķľ ‘ň”√…Ó∂»—ßŌįÕݬÁĶń ĪļÚ£¨≤ĽŅ…Ī‹√‚ĶńĽŠŇŲĶĹĺŪĽż…Ůĺ≠ÕݬÁ£®Convolutional Neural Networks, CNN£©°£CNNĶń‘≠ņŪ «ń£∑¬»ňņŗ…Ůĺ≠‘™Ķń–ň∑‹Ļż≥Ő£ļīůń‘÷–Ķń“Ľ–©…Ůĺ≠ŌłįŻ÷Ľ”–‘ŕŐō∂®∑ĹŌÚĶńĪŖ‘Ķīś‘ŕ Ī≤Ňń‹◊Ų≥Ų∑ī”¶°£īÚłŲĪ»∑Ĺ£¨ĶĪő“√«∑«≥£ĹŁĺŗņŽĶōĻŘ≤ž“Ľ’Ň»ňŃ≥Õľ∆¨ Ī£¨’‚ ĪļÚő“√«Ķńīůń‘÷–÷Ľ”–“Ľ≤Ņ∑÷…Ůĺ≠‘™ «ĪĽľ§ĽÓĶń£¨ő“√«“≤÷Ľń‹ŅīĶĹ»ňŃ≥…ŌĶńŌŮňōľ∂ĪūĶ„£¨ĶĪő“√«į—ĺŗņŽ“ĽĶ„Ķ„ņ≠Ņ™£¨īůń‘∆šňŻ≤Ņ∑÷Ķń…Ůĺ≠‘™Ĺ꼊ĪĽľ§ĽÓ£¨ő“√«“≤ĺÕŅ…“‘ĻŘ≤žĶĹ»ňŃ≥ĶńŌŖŐű°ķÕľįł°ķĺ÷≤Ņ°ķ’ŻłŲ»ňŃ≥£¨’‚ĺÕ «“Ľ≤Ĺ≤ĹĽŮĶ√łŖ≤„Őō’ųĶńĻż≥Ő°£ Õľ4£ļĽýĪĺÕÍ’ŻĶń…Ó∂»—ßŌįŃų≥Ő …Ó∂»—ßŌįĶńļ√ī¶ «Ō‘∂Ý“◊ľŻĶń ®C Őō’ųĪŪīÔń‹Ń¶«Ņ£¨”–ń‹Ń¶ĪŪ ĺīůŃŅĶń żĺ›£Ľ‘§—ĶŃ∑ «őřľŗ∂Ĺ—ĶŃ∑£¨Ĺŕ °īůŃŅ»ňѶĪÍ ∂Ļ§◊ų£ĽŌŗĪ»īęÕ≥Ķń…Ůĺ≠ÕݬÁ£¨Õ®Ļż÷ū≤„—ĶŃ∑Ķń∑Ĺ∑®ĹĶĶÕŃň—ĶŃ∑ń—∂»£¨»Á–ŇļŇň•ľűĶńő Ő‚°£…Ó∂»—ßŌį‘ŕļ‹∂ŗŃž”ÚĪ»«≥≤„—ßŌįň„∑®ÕýÕý”–20-30%ĶńŐŠłŖ£¨«ż Ļ—–ĺŅ’Ŗ∑ĘŌ÷–¬īů¬Ĺ“Ľį„”ŅŌÚ…Ó∂»—ßŌį’‚“ĽŃž”Ú°£ |…Ó∂»—ßŌįĶń÷ō“™∑Ę’ĻŃž”Ú …Ó∂»—ßŌį ◊Ō»‘ŕÕľŌŮ°Ę…ý“ŰļÕ”Ô“Ś ∂Īū»°Ķ√Ńň≥§◊„ĶńĹÝ≤Ĺ£¨ŐōĪū «‘ŕÕľŌŮļÕ…ý“ŰŃž”ÚŌŗĪ»īęÕ≥ň„∑®īůīůŐŠ…żŃň ∂Īū¬ °£∆š Ķ“≤ļ‹»›“◊ņŪĹ‚£¨…Ó∂»—ßŌį «ń£∑¬»ňņŗīůń‘…Ůĺ≠ł–÷™Õ‚≤Ņ ņĹÁĶńň„∑®£¨∂Ý◊Ó≥£ľŻĶńÕ‚≤Ņ◊‘»Ľ–ŇļŇń™Ļż”ŕÕľŌŮ°Ę…ý“ŰļÕőń◊÷£®∑«”Ô“Ś£©°£ ÕľŌŮ ∂Īū£ļÕľŌŮ «…Ó∂»—ßŌį◊Ó‘Á≥Ę ‘ĶńŃž”Ú°£YannLeCun‘Á‘ŕ1989ńÍĺÕŅ™ ľŃňĺŪĽż…Ůĺ≠ÕݬÁĶń—–ĺŅ£¨»°Ķ√Ńň‘ŕ“Ľ–©–°Ļśń££® ÷–ī◊÷£©ĶńÕľŌŮ ∂ĪūĶń≥…ĻŻ£¨Ķę‘ŕīůŌŮňōÕľ∆¨ ∂Īū…Ō≥Ŕ≥Ŕ√Ľ”–ÕĽ∆∆£¨÷ĪĶĹ2012ńÍHintonļÕňŻ—ß…ķ‘ŕImageNet…ŌĶńÕĽ∆∆£¨≤Ň Ļ ∂Īūĺę∂»ŐŠłŖŃň“ĽīůĹō°£2014ńÍ£¨xg÷–őńīů—ßĹŐ ŕŐņŌĢҳўĶľĶńľ∆ň„Ľķ ”ĺű—–ĺŅ◊ťŅ™∑ĘŃň√Żő™DeepIDĶń…Ó∂»—ßŌįń£–Õ£¨‘ŕ»ňŃ≥ ∂Īū…ŌĽŮĶ√Ńň99.15%Ķń ∂Īū¬ £¨≥¨ĻżŃň»ňņŗ»‚—ŘĶńĶń ∂Īū¬ £®97.52%£©°£ ”Ô“Ű ∂Īū£ļ”Ô“Ű ∂Īū≥§∆ŕ“‘ņī∂ľ Ļ”√ĽžļŌłŖňĻń£–ÕņīĹ®ń££¨ĺ°Ļ‹ĹĶĶÕŃň”Ô“Ű ∂ĪūĶńīŪőů¬ £¨Ķę‘ŕ”–‘Ž“ŰĶń Ķľ ◊‘»ĽĽ∑ĺ≥÷–īÔ≤ĽĶĹŅ…”√Ķńľ∂Īū°£÷ĪĶĹ…Ó∂»—ßŌįĶń≥ŲŌ÷£¨ ĻĶ√ ∂ĪūīŪőů¬ ‘ŕ“‘Õý◊Óļ√ĶńĽýī°…ŌŌŗ∂‘Ō¬ĹĶ30%“‘…Ō£¨īÔĶĹ…Ő“ĶŅ…”√Ķńňģ∆Ĺ°£ ◊‘»Ľ”Ô—‘ī¶ņŪ£®NLP£©£ļľī ĻĶĹŌ÷‘ŕ£¨…Ó∂»—ßŌį‘ŕNLPŃž”Ú≤Ę√Ľ”–»°Ķ√ŌŮÕľŌŮ ∂ĪūĽÚ’Ŗ”Ô“Ű ∂ĪūŃž”Úń«—ýĶń≥…ĺÕ£¨Ľý”ŕÕ≥ľ∆Ķńń£–Õ»‘»Ľ «NLPĶń÷ųŃų£¨Ō»Õ®Ļż”Ô“Ś∑÷őŲŐŠ»°ĻōľŁī °ĘĻōľŁī ∆•Ňš°Ęň„∑®Ň–∂®ĺš◊”Ļ¶ń‹£®’“≥ŲĺŗņŽ’‚łŲĺš◊”◊ÓĹŁĶńĪÍ ∂ļ√Ķńĺš◊”£©£¨◊Óļů‘ŔņŻ”√ŐŠ«į◊ľĪłĶń żĺ›Ņ‚ŐŠĻ©”√Ľß š≥ŲĹŠĻŻ°£Ō‘»Ľ£¨’‚√ųŌ‘Őł≤Ľ…Ō÷«ń‹£¨÷Ľń‹ň„“Ľ÷÷ň—ňųĻ¶ń‹Ķń ĶŌ÷£¨∂Ý»Ī∑¶’ś’żĶń”Ô—‘ń‹Ń¶°£ ő™ ≤√ī…Ó∂»—ßŌį‘ŕNLPŃž”ÚĹÝ’ĻĽļ¬ż?’‚ «“Úő™£¨∂‘”Ô“ŰļÕÕľŌŮņīňĶ£¨∆šĻĻ≥…‘™ňō£®¬÷ņ™°ĘŌŖŐű°Ę”Ô“Ű÷°£©≤Ľ”√ĺ≠Ļż‘§ī¶ņŪ∂ľń‹«Śőķ∑ī”≥≥Ų“™ ∂ĪūĶń∂‘Ōů£¨Ņ…“‘÷ĪĹ”∑ŇĶĹ…Ůĺ≠ÕݬÁņÔĹÝ–– ∂Īū°£∂ݔԓŚ ∂Īūīů≤ĽŌŗÕ¨£ļ»ňňĶĶń√Ņ嚼į≤Ę∑«◊‘»Ľ–ŇļŇ£¨ļ¨”–∑ŠłĽ∂ŗĪšĶń”Ô“Ś£¨∂‘ňŁĶńņŪĹ‚–Ť“™≤őŅľ…ŌŌ¬őń”Ôĺ≥Ķń£¨”– ĪļÚĽĻĽŠ…śľįĶĹīůŃŅĶńőńĽĮĪ≥ĺį÷™ ∂°£“Úīň£¨∑¬»ňņŗīůń‘ ∂ĪūĽķ÷∆Ĺ®ŃĘĶń…Ó∂»—ßŌį£¨∂‘ĺ≠Ļżő“√«»ňņŗīůń‘ī¶ņŪĶńőń◊÷–ŇļŇĶńņŪĹ‚£¨–ßĻŻ∑ī∂Ý≤Ó«Ņ»ň“‚°£łýĪĺ…ŌņīňĶ£¨Ō÷‘ŕĶńň„∑®ĽĻ Ű”ŕ»ű»ňĻ§÷«ń‹£¨Ņ…“‘»•įÔ»ňņŗŅžňŔĶń◊‘∂Į÷ī––£® ∂Īū£©£¨»ī≤Ľń‹ņŪĹ‚’‚ľĢ ¬«ťĪĺ…Ū°£ |…Ó∂»—ßŌįĶńŐŰ’ĹļÕ∑Ę’Ļ∑ĹŌÚ ‹“ś”ŕľ∆ň„ń‹Ń¶ĶńŐŠ…żļÕīů żĺ›Ķń≥ŲŌ÷£¨…Ó∂»—ßŌį‘ŕľ∆ň„Ľķ ”ĺűļÕ”Ô“Ű ∂ĪūŃž”Ú≥…ĺÕž≥»Ľ£¨≤ĽĻżő“√«“≤ŅīĶĹŃň“Ľ–©…Ó∂»—ßŌįĶńĺ÷Ōř–‘£¨ōĹīżĹ‚ĺŲ£ļ - …Ó∂»—ßŌį‘ŕ—ß űŃž”Ú»°Ķ√Ńň≤ĽīŪĶń≥…ĻŻ£¨Ķę‘ŕ…Ő“Ķ…Ō∂‘∆ů“ĶįÔ÷ķ≤Ę≤Ľ√ųŌ‘°£“Úő™…Ó∂»—ßŌį «“ĽłŲ”≥…šĶńĻż≥Ő£¨ī” š»ŽA”≥…šĶĹ š≥ŲB£¨∂Ý‘ŕ∆ů“ĶĽÓ∂Į÷–»ÁĻŻő““—ĺ≠”Ķ”–Ńň’‚—ýĶńA°ķB”≥…š£¨ő™ ≤√īĽĻ–Ť“™Ľķ∆ų—ßŌįņīÕ∆∂Ōńō£Ņ»√Ľķ∆ų◊‘ľļ‘ŕ żĺ›÷–—į’“’‚÷÷”≥…šĻōŌĶĽÚ’ŖĹÝ––yc£¨ńŅ«įĽĻīś‘ŕļ‹īůń—∂»°£
- »Ī∑¶ņŪ¬ŘĽýī°£¨’‚ «ņß»Ň◊Ň—–ĺŅ’ŖĶńő Ő‚°£Ī»»ÁňĶ£¨AlphaGo’‚ŇŐ∆Ś”ģŃň£¨ń„ļ‹ń—Ň™∂ģňŁ «‘ű√ī”ģĶń°£Ņ…“‘ňĶ£¨…Ó∂»—ßŌį «“ĽłŲļŕŌš◊”£¨…Ůĺ≠ÕݬÁ–Ť“™∂ŗ…ŔłŲ“Ģ≤„ņī—ĶŃ∑£¨ĶĹĶ◊–Ť“™∂ŗ…Ŕ”––ßĶń≤ő żĶ»£¨∂ľ√Ľ”–ļ‹ļ√ĶńņŪ¬ŘĹ‚ Õ°£
- …Ó∂»—ßŌį–Ť“™īůŃŅĶń—ĶŃ∑—ýĪĺ°£”…”ŕ…Ó∂»—ßŌįĶń∂ŗ≤„ÕݬÁĹŠĻĻ£¨ń£–ÕĶń≤ő ż“≤ĽŠ‘Ųľ”£¨»ÁĻŻ—ĶŃ∑—ýĪĺ≤ĽĻĽīů «ļ‹ń— ĶŌ÷Ķń£¨–Ť“™ļ£ŃŅĶńĪÍľ« żĺ›£¨Ī‹√‚≤ķ…ķĻżń‚ļŌŌ÷Ōů£®overfitting£©∂Ý≤Ľń‹ļ‹ļ√ĶńĪŪ ĺ’ŻłŲ żĺ›°£
- …Ó∂»—ßŌį‘ŕNLPŃž”ÚĽĻ√śŃŔļ‹īůŐŰ’Ĺ£¨ńŅ«įĶńń£–Õ»Ī∑¶ņŪĹ‚ľįÕ∆ņŪń‹Ń¶°£
“Úīň£¨…Ó∂»—ßŌįĹęņīĶń∑Ę’Ļ∑ĹŌÚ“≤Ĺę…śľįĶĹ“‘…Ōő Ő‚ĶńĹ‚ĺŲ°£Hinton°ĘLeCunļÕBengio»żőĽAIŃž–š‘Ý‘ŕļŌ÷ÝĶń“Ľ∆™¬Řőń£®Deep Learning£©ĶńĹŠő≤ŐŠ≥ŲŃň…Ó∂»—ßŌįĶńőīņī∑Ę’Ļ∑ĹŌÚ£ļ - őřľŗ∂Ĺ—ßŌį°£ňš»Ľľŗ∂Ĺ—ßŌį‘ŕ…Ó∂»—ßŌį÷–ĪŪŌ÷≤Ľň◊£¨≥¨ĻżŃňőřľŗ∂Ĺ—ßŌį‘ŕ‘§—ĶŃ∑÷–Ķń–ßĻŻ£¨Ķę»ňņŗļÕ∂ĮőÔĶń—ßŌį∂ľ «őřľŗ∂Ĺ—ßŌį∑Ĺ Ĺ£¨ő“√«ł–÷™ ņĹÁ∂ľ «Õ®Ļżő“√«◊‘ľļĶńĻŘ≤ž£¨“Úīň»Ű“™łŁľ”Ŕţ»ňņŗīůń‘Ķń—ßŌįń£ Ĺ£¨őřľŗ∂Ĺ—ßŌį–Ť“™Ķ√ĶĹłŁļ√Ķń∑Ę’Ļ°£
- «ŅĽĮ—ßŌį°£‘Ų«Ņ—ßŌį÷łĶń «ī”Õ‚≤ŅĽ∑ĺ≥ĶĹ––ő™”≥…šĶń—ßŌį£¨Õ®ĻżĽý”ŕĽōĪ®ļĮ żĶń ‘īŪņī∑ĘŌ÷◊ӔҖ–ő™°£”…”ŕ‘ŕ Ķľ ‘ň”√÷– żĺ›ŃŅ «Ķ›‘ŲĶń£¨‘ŕ–¬ żĺ›÷–ń‹∑Ů—ßŌįĶĹ”––ßĶń żĺ›≤Ę◊Ų≥Ų–ř’ż∑«≥£÷ō“™£¨…Ó∂»+«ŅĽĮ—ßŌįŅ…“‘ŐŠĻ©ĹĪņÝĶń∑īņ°Ľķ÷∆»√Ľķ∆ų◊‘÷ųĶń—ßŌį£¨Ķš–Õįłņż «AlphaGo°£
- ņŪĹ‚◊‘»Ľ”Ô—‘°£ņŌĹŐ ŕ√«ňĶ£ļłŌĹŰ»√Ľķ∆ų∂Ń∂ģ»ňņŗĶń”Ô—‘į…£°
- «®“∆—ßŌį°£į—ņŻ”√īů żĺ›—ĶŃ∑ļ√Ķńń£–Õ«®“∆‘ň”√ĶĹ”––ß żĺ›ŃŅ–°Ķń»őőŮ…Ō£¨“≤ĺÕ «į——ßĶĹĶń÷™ ∂”––ßĶńĹ‚ĺŲ≤ĽÕ¨ĶęŌŗĻōŃž”ÚĶńő Ő‚°£’‚ ¬«ťŅī∆ūņīļ‹√ņļ√£¨Ķęń—Ķ„‘ŕ”ŕ“——ĶŃ∑ļ√Ķńń£–Õīś‘ŕ◊‘ő“∆ę≤Ó£¨–Ť“™łŖ–ßň„∑®»•ŌŻ≥ż’‚–©∆ę≤Ó°£łýĪĺ…ŌņīňĶ£¨ĺÕ «»√Ľķ∆ųŌŮ»ňņŗ“Ľ—ýĺŖĪłŅžňŔ—ßŌį–¬÷™ ∂Ķńń‹Ń¶°£
◊‘…Ó∂»—ßŌįĪĽHinton‘ŕ°∂Science°∑∑ĘĪŪ“‘ņī£¨∂Ő∂ŐĶń≤ĽĶĹ10ńÍ ĪľšņÔ£¨īÝņīŃň»ňĻ§÷«ń‹‘ŕ ”ĺű°Ę”Ô“ŰĶ»Ńž”ÚĶńÕĽ∆∆–‘ĹÝ≤Ĺ£¨‘Ŕ“ĽīőŌ∆∆ūņī»ňĻ§÷«ń‹Ķń»»≥Ī°£ňš»ĽńŅ«į»‘»Ľīś‘ŕļ‹∂ŗ≤Ó«Ņ»ň“‚ĶńĶō∑Ĺ£¨ĺŗņŽ«Ņ»ňĻ§÷«ń‹ĽĻ”–ļ‹īů≤Óĺŗ£¨Ķę…Ó∂»—ßŌį «ńŅ«į◊ÓŔţ»ňņŗīůń‘‘ň◊ų‘≠ņŪĶńň„∑®°£Ōŗ–Ň‘ŕĹęņī£¨ňś◊Ňň„∑®ĶńÕÍ…∆“‘ľį żĺ›ĶńĽżņŘ£¨…ű÷Ń”≤ľĢ≤„√ś∑¬»ňņŗīůń‘…Ůĺ≠‘™≤ńŃŌĶń≥ŲŌ÷£¨…Ó∂»—ßŌįĹ꼊łŁĹÝ“Ľ≤ĹÕ∆∂Į»ňĻ§÷«ń‹Ķń∑Ę’Ļ°£
| 


 /1
/1 
 |Archiver| ÷Ľķįś|–°ļŕő›|…¬ICPĪł15012670ļŇ-1
|Archiver| ÷Ľķįś|–°ļŕő›|…¬ICPĪł15012670ļŇ-1








 ∑ĘĪŪ”ŕ 2022-10-8 09:25:30
∑ĘĪŪ”ŕ 2022-10-8 09:25:30

 ’≤ō
’≤ō